
The daily work of Workforce Management (WFM) teams requires the precise updating of certain indicators in order to size the necessary capacity, whether in terms of hours, human resources or required concurrency.
In this note we will take a look at the most commonly used sizing processes, from the perspective of those who use the processes on a day-to-day basis and those who need to decide and calibrate based on the information received.
Prior to the Capacity process
Even after many years of experience and in leadership positions in WFM Operations, many analysts believe that the historical-based volume forecasting process is part of the capacity sizing process.
We may describe this process in detail in the future, but we want to list three important reasons why this process is unique and isolated:
1) The forecast becomes only an input to be used for sizing; it is only a variable to be used in a statistical model. Its individual process can be modified without impacting the sizing process.
2) The forecasting process is stochastic, meaning that events change probabilistically as time passes. For example, the forecast includes seasonality change factors, product launches, general failures that modify the probability of contact entry.
3) In some cases, the forecasting process is not implemented by the Workforce team; only the results are received from the External Client, or from a central planning team (GRP – Global Resource Planning).

The three most commonly used processes for determining the Required Capacity are as follows
What is the most convenient capacity sizing process? Let’s review in detail three of the most used processes, what are the pros and cons of each of them.
1) Empirical Process
(or “busy boss opening the calculator app”)
Para fines educativos le vamos a llamar “proceso”, pero lo cierto es que este cálculo es una de las “cajas negras” más sencillas y usadas en la industria para validar de forma simple un proceso más complejo. This process consists of consecutive arithmetic operations that lead us to determine the capacity required in hours or in human resources. Many leaders do not have time or do not find it within their reach to have to know in-depth details of criteria or formulas.
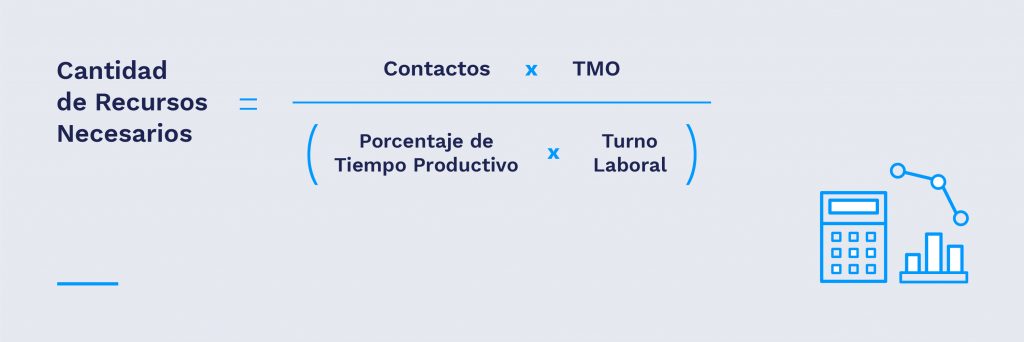
In this simple case we can afford to give an example.
Let’s say we expect to receive 20000 calls in a week and each call has an average duration of 5 minutes. We should prepare for a speaking time of 5 minutes. 5×20000 = 100000 minutes (1667 hours). Let’s say an agent works 40 hours per week, de las cuales un 70% del tiempo esperamos que esté efectivamente al teléfono. This gives a useful time per agent of 40 * 70% = 28 weekly hours. Doing the corresponding division we obtain that with 60 agents we fulfill the attention.
Pros of the Empirical process:
-Easy to understand.
-Aplicación rápida.
-Fast application applied depending on the type of contract.
–It allows to detect possible errors in more complex methods.
Cons of the Empirical process:
–Wrong expectations. The actual outcome of specialized processes can vary greatly from this general exercise.
–It does not take into account seasonal variations, nor variables such as absenteeism/retention.
-The causal determinism on which these arithmetic solutions are based leaves no room for the generation of complex scenarios.
2) Erlang
(or “we all use it, but we don’t really know it.”)
The process for applying the Erlang distribution is based on the theory of Danish mathematician Agner Erlang (1917) to examine the number of contacts that can be made at the same time to telephone operators changing stations.
The formula widely known and used in the contact center world is known as Erlang C and is based on the following assumptions:
a. The time between call arrivals is a random variable with exponential distribution of parameter according to how many calls are expected to be received in an interval. This hypothesis is highly realistic.
b. The duration of a call is also a random variable with an exponential distribution whose parameter is adjusted to respect the TMO. This second hypothesis is not realistic in practice.
c. The caller waits indefinitely in queue until his call is answered. There are no dropouts; another hypothesis that is not realistic.
A later formula known as Erlang A (1946) -although developed by the Swede Conny Palm-, allows the expected number of dropouts to be calculated by adding to the Erlang C assumptions a patience that is also modeled with an exponential variable. This formula undoubtedly helps to complement Erlang C, but it does not solve the problem since it does not provide a service level forecast by itself.
It is common to receive only an Excel with a macro module ready to use and mechanical instructions on how to apply the Erlang code. And in the case of robust WFM systems, the code comes ready to be part of the sizing process based on segmented historical information.
Erlang Pros:
– It is a process familiar to all BPO operations today.
– Customized versions are used to generate calculations on other channels.
– In addition to indicating the required agents, it allows the forecasting of other indicators such as Service Level and Average Response Time.
Cons of Erlang:
– The call duration assumption does not match reality.
– If the process receives more parameters than necessary, it can create overestimates in its result that are not always interpreted correctly. The vast majority of teams take the result without checking if it contains an unneeded level of over-fitting.
– El modelo Erlang no contempla abandonos. Para esta aplicación de la fórmula se parte del supuesto de que todas las llamadas esperan de forma indefinida hasta que son atendidas.
– Although it is a common practice nowadays, Erlang’s applied formula is designed for a single service. It does not contemplate that current agents are trained in various lines of business and are dynamically moved throughout the day to meet coverage needs.Multichannel allocation or overflow per line of business cannot be sized. This is one of the main reasons for oversizing in multichannel operations when projecting Erlang-based resources.
– The original formula assumes a finite number of incoming contacts only. Transfers made from other lines of service, direct calls to an extension, additional calls made by contacts who hang up and call back are not taken into account in the base Erlang. To compensate for these occurrences, many teams adjust with incremental values according to holidays, offer or product launch days and intervals with historical spikes.
3) Custom Simulation
(or “yes, we can do that and more, based on mathematics.”)
Taking into account the benefits of the current computational capacity, we start from a simplification of the mathematical simulation process. Simulate at an accelerated pace every call of the day with all its attributes:
– who takes the call
– if it meets the service level
– whether or not to abandon
– how long does it take
– if the agent takes another contact immediately or if he goes on break
A robust statistical model allows us in a matter of minutes to perform different simulations for a whole day or weeks.. And based on trends, it allows defining the most accurate projection according to the historical information and criteria used to feed the model.
Pros de la Simulación Personalizada:
– Real criteria such as waiting time or dropouts are applied.
– The algorithm generates calls and assigns them to available agents.
– Simulates a full day in milliseconds allowing all relevant indicators to be displayed.
– It allows repeating the day many times, to give more realistic results of scenarios that could arise (it gives an idea of what is known in statistics as variance) instead of just giving the average result.
– Ability to simulate agents with multiskill.
Cons of Custom Simulation:
– High computational capacity required. We are talking about dedicated servers and a large amount of information processed to create each of the simulations.
–A structured interface is required to be able to process input data and calibrate specific details such as multiskill agent processing, changes in absenteeism trends and auxiliary usage such as holidays or anomalies, agent profiles, etc. Without this facility, managing the statistical model requires a dedicated person.
-Being able to implement this solution from scratch requires an advanced level of exact sciences and WFM expertise that is difficult to achieve.
Beyond the chosen process, there is one critical role: that of the Workforce Management team.

Considering the benefits and pitfalls of each of the sizing processes, the factor that will actually make the difference between the success and failure of these planning cycles is the level of freedom allowed for WFM teams to calibrate the results.
For example, real-time analysts can easily account for anomalies in results
(human factors, emergencies related to connectivity or software, among others). But many times do not have a structured way of documenting this knowledge generated on the front lines and being able to include it effectively in the new planning cycles.
The sizing process should include parallel business intelligence processes, to capitalize on process errors, human errors and anomalies external to the process. And then replicate that learning to the rest of our teams. Just like the well-known “if it’s not measured, it’s no good”, we have the opportunity to apply the following on a daily basis: “Today’s computing power, such as Artificial Intelligence, will not replace analysts and creators, it will only make our work more human.”
The more we share knowledge and train our teams, opening the door to forums where these processes are questioned, validated and improved; the more we support our talent within WFM, the better results these processes and others related to BPO cycles will have. At the end of the day, it is a business of people for people.


